

5 strategies for getting system fixes approved (when engineering says no)
From "copy"writer to systems thinker: Your playbook for organizational advocacy

You’re trying to convince your engineering team to fix a broken error flow. Instead of just writing a better error message, you want to actually prevent the error—add inline validation, constrain the input, design it so users can’t mess it up in the first place.
They nod. Makes sense. Then they hit you with:
“We don’t have budget for this quarter. Just write a generic error message for now. We’ll fix the system later.”
You know “later” never comes.
This is the pushback you’ll face over and over. Not “it’s too expensive” but “it’s not prioritized against other features right now.”
Here’s the thing: Error messages aren’t writing problems—they’re system design problems. The best error message? The one users never see because you prevented the error at the design level.
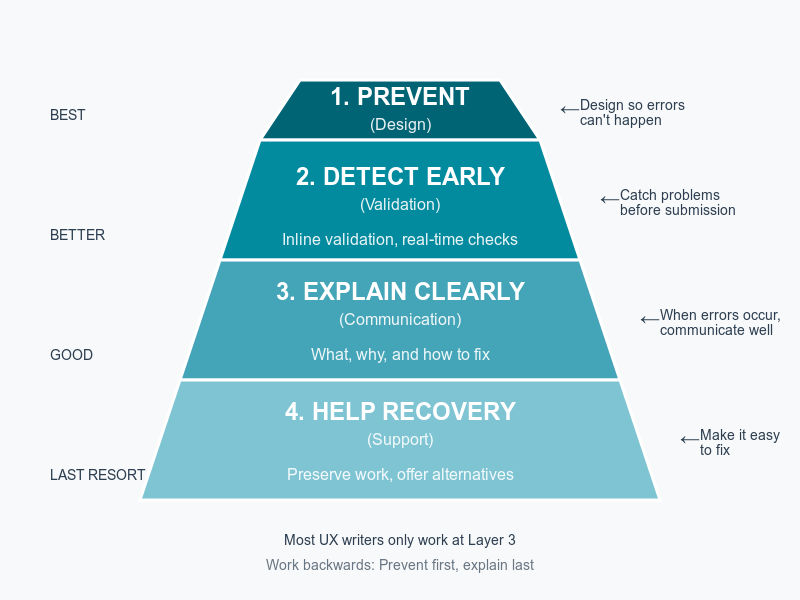
The Error Prevention Pyramid above shows four layers of error handling:
Layer 1 (Prevention): Design so errors can’t happen
Layer 2 (Early Detection): Catch problems before submission
Layer 3 (Clear Communication): Write better error messages
Layer 4 (Recovery Support): Help users fix problems
Most content designers? They only work at Layer 3—writing the error message. That’s the worst place to solve the problem, but it’s often the only layer anyone asks you to touch.
This article is about getting Layers 1 and 2 approved in real organizations with real constraints. Because knowing the right approach means nothing if you can’t actually get it implemented.
You need more than good ideas. You need data that’s impossible to ignore.
The playbook: 5 strategies for getting system fixes approved
Quantify support cost (The hard ROI)
The pilot program approach (The legacy system fix)
The negotiation ladder (The compromise)
The partnership method (The political hack)
Use business intelligence data (The high-impact case)
Let’s break down each strategy.
Strategy 1: Quantify support cost (The hard ROI)
You say: …better UX…
Engineering/product hears: Nice to have. Soft metric. Can wait.
You say: …this will reduce 200 support tickets per month…
Engineering/product hears: Hard cost savings. Measurable ROI. Business impact.
THAT is what you need!
How to build the ROI case
Step 1: Partner with customer support
Ask three questions:
How many tickets do we get for [this specific error]?
How long does each ticket take to resolve? (average minutes)
What’s the cost per ticket? (agent time × hourly rate)
Step 2: Do the math
Use this formula Content ROI formula a.k.a Cost of problem:
Annual Cost =
(Tickets per month × Avg Resolution Time × Agent Hourly Rate) × 12
For example:
200 tickets/month for “Invalid credit card” error
15 minutes average resolution time
$30/hour agent cost
Monthly cost: 200 × 0.25 hours × $30 = $1,500
Annual cost: $1,500 × 12 = $18,000That’s $18,000 per year for ONE poorly-designed error flow!!
Step 3: Calculate the fix cost
Fix Cost = Engineering hours × Hourly rateIn this example:
Layer 2 (inline validation): ~20 hours of engineering time
Engineering rate: ~$150/hour
Fix cost: $3,000
Step 4: Present the business case
Put it together:
This error generates 200 support tickets monthly, costing $18,000 annually in agent time. Fixing the system with inline validation (Layer 2) will cost ~20 hours of engineering time upfront ($3,000) and eliminate 80% of these tickets.
ROI: We break even in 2 months. Then we save $14,400 annually.
The language that works
Don’t say this:
Users will be frustrated
This is bad UX
It’s not a good experience
Say this instead:
This costs $18K annually in support
Reduces tickets by 80%
ROI in 2 months, then $14K savings annually
This actually happened with me.
I faced exactly this scenario. Engineering wanted ONE generic error message for 10 different error types. I pushed back: “Users will raise tickets anyway AND be frustrated. Better to give the solution in the error message.”
They agreed conceptually but said creating 10 help centre articles (linked from errors) would burden the support team.
I partnered with support and did the above calculations to show the cost savings.
I still needed senior management backing to get it prioritized. But it gave me a good shot at convincing them. Not with opinions of ‘better UX’ but a promise of 'bottom line impact’.
Content designers are often perceived as “people who write pretty sentences.” You need data to be taken seriously as a systems thinker.
Numbers change everything!
Strategy 2: The pilot program approach (For legacy systems)
The objection: This system is 100 years old. We can’t rebuild it without massive effort. Just improve the error messages for now.
Your counter-move: The pilot program
Don’t argue for a full rebuild. Propose a contained experiment instead.
How to structure a pilot program
Step 1: Identify 2-3 high-traffic, high-impact flows
Ask:
Where do users get stuck most?
Where do support tickets concentrate?
Which flows affect revenue/conversion?
Step 2: Propose a pilot: Fix the SYSTEM for these flows only
Implement Layer 1 (Prevention) + Layer 2 (Detection) for JUST these screens
Measure before/after:
Support tickets
Completion rate
Time-to-complete
User satisfaction (if tracked)
Treat it as a test case for the full product
Step 3: Use pilot results to build the case for broader changes
Present results:
Pilot reduced tickets by 65% for this flow
Completion rate increased 40%
Time-to-complete dropped by 3 minutes
When I worked on an Enterprise platform (legacy system)
I worked on a suite of enterprise products that had been in place for over 100 years. While they developed their digital platform in the 90s and updated the UI, the processes and UX remained unchanged.
Inline validation and error prevention were technically impossible without a complete rebuild.
I proposed a pilot program.
Identified 3 high-traffic flows serving a small, high-impact audience segment (internal sales team using the order entry system)
Proposed testing the new system, flows, and content on THOSE flows only
Measured before/after: tickets dropped 60%, order completion time improved by 5 minutes per order
Built a case for complete revamp using pilot data
And it worked!
I didn’t ask for everything at once. I asked for a measurable experiment with clear success metrics. If it fails, the cost is contained. If it succeeds, which it did in this case, I had proof for broader investment.
Strategy 3: The negotiation ladder (When Layer 1 isn’t feasible)
If you can’t get full prevention (Layer 1), negotiate down the ladder:
Pitch for: Layer 1 (Full Prevention)
↓ Blocked?
Negotiate for: Layer 2 (Early Detection)
↓ Blocked?
Negotiate for: Layer 3+ (Better Messages + Recovery)Layer 2 is the optimal compromise.
Lower technical lift: No form redesign, no new components—just validation logic
Low engineering effort: Can be added incrementally without rebuilding anything
Immediate feedback: Catches 70-80% of errors before submission
Better UX than Layer 3: Users see problems instantly, not after a server round-trip
High ROI: Solves most format/typo errors with minimal investment
Easier to sell: Product/engineering can see the value without major commitment
Example negotiation
I understand we can’t change the form design this quarter (Layer 1). Can we add inline validation as the user types (Layer 2)? It’s lower engineering effort and still prevents the frustration of submitting and getting a generic error.
This compromise worked for me, but it required persistence AND backing from senior management. The perception issue is real: we’re not seen as systems thinkers by default. So, we have to build credibility over time.
Deliver on Layer 2 implementations
Track metrics (show ticket reduction)
Use success to argue for Layer 1 next quarter
Strategy 4: The partnership method (The political hack)
Sometimes you don’t have the organizational power to tell engineering what to do. Sometimes content design just isn’t seen as strategic. You need workarounds.
Partner with design
If it’s not getting approved as a content solution, frame it as a design solution
When the design file is being created, suggest small changes to the designer
Get it into the prototype/mock-up before engineering sees it
Once it’s in the design, engineering implements what they see
Document system debt
I keep a “system debt” log and pass notes to the relevant teams asking them to include small fixes in their sprints.
Most teams have budget for small improvements (~3 hours effort). If you make it easy (clear ask, low effort, visible impact), they’ll include it.
This isn’t ideal, I know. You shouldn’t have to “sneak” good UX into the product.
But until content design is perceived as strategic (not decorative), these sly tactics work.
What really helps long-term: Building relationships
Have one-on-one candid chats with engineers
Understand their constraints first (extend empathy)
Ask: “What are the levers or constraints I’m not aware of?”
Speak their language: frame problems in their terms
Strategy 5: Use business intelligence data (The high-impact case)
Go beyond support tickets to show business impact.
Step 1: Get page traffic data
Work with your analytics or BI team to answer:
Which flows have highest traffic?
Where do users drop off?
What’s the conversion rate for each step?
Step 2: Get error data
Ask:
Which errors occur most frequently?
Where do users get stuck in the flow?
What’s the abandonment rate after hitting an error?
Step 3: Build your case with BI team
This error affects 10,000 users monthly on our highest-traffic flow (checkout). Current abandonment rate after error: 40%. If we reduce errors by 60% with inline validation, we recover 2,400 checkouts/month.
If you can tie it to revenue:
Average order value: $50. Recovering 2,400 checkouts = $120,000 additional monthly revenue. Annual impact: $1.44 million.
When I encountered a similar issue
I reached out to the BI team and got:
Traffic data: 50,000 users/month hit the “create account” flow
Error frequency: 8,000 users (16%) hit the “invalid email” error
Support tickets: 200/month asking “why can’t I create an account?”
My pitch:
16% of users hit this error. We can reduce it to 3% with inline email validation (Layer 2). That’s 6,500 fewer frustrated users monthly, 160 fewer support tickets, and a cleaner conversion funnel.
Cost: 15 engineering hours (~$2,250)
Savings: $2,400/month in support costs + better conversion
They approved it!
When you won’t win: Managing system debt
The uncomfortable truth: Sometimes you won’t win.
You’ll write the specific error messages with actionable solutions. You’ll present the ROI. You’ll propose a pilot. And they’ll still say:
This creates more work for support (creating help docs)
We can’t maintain 10 different messages
Just give us one generic message
You’ll document the system debt. You’ll add it to the backlog. And it’ll never get prioritized.
This happens. It’s not your failure.
So what can you do?
1. Keep documenting (The system debt log)
The problem’s cost (tickets, time, frustration)
Your proposed solution
The ROI calculation
Date you flagged it
When the problem gets worse, or when leadership asks “why are support costs high?”, you have documentation showing you identified and costed the solution months ago.
You’ll come across as proactive and solution-oriented, and the fix process will move faster.
2. Pick your battles (The high-impact focus)
Well, you can’t fix everything. Focus on:
Highest-traffic flows first
Flows that affect revenue/conversion
Flows with highest support cost
Flows where you have data proving impact
Don’t fight for every error message. Save your political capital for the fights that matter.
3. Celebrate small wins (The momentum builder)
Got Layer 2 approved instead of Layer 1? That’s a win.
Why?
You prevented 70% of errors (vs. 0% if you only wrote a better message)
You proved you can deliver ROI
You built credibility for the next request
You showed you’re a systems thinker, not just a writer
Track your wins:
Reduced tickets by 60% on the signup flow
Improved completion rate by 25% on checkout
Saved $8,000 annually in support costs
Use these wins to build the case for bigger changes.
Remember: You’re playing the long game.
Each time you:
Present data instead of opinions
Calculate ROI instead of saying “better UX”
Propose pilots instead of full rebuilds
Show business impact instead of user frustration
You’re building credibility as a systems thinker.
Over time, your requests get approved faster. Over time, product and engineering start asking YOU for system-level recommendations. Over time, you’re not fighting to be heard—you’re expected to weigh in on system design.
That’s the goal.
Next post on Dec 19 - Prompt engineering for Content Design that gets consistent, on-brand copy.
See you later,
— Mansi
Your UX Writing Bud
Found this useful? Here’s how to apply it.
Calculate your ROI - Pick one error flow in your product and run the numbers. See what it’s actually costing you.
Share your results - Got a system fix approved using these strategies? DM me on Substack. I want to hear about it.
Propose a pilot - Find your highest-impact flow and pitch a contained experiment. Tell us how it went.
Support this work - If this playbook changed your approach, buy me a coffee/book.
UX Writing Bud delivers frameworks and systems for content designers every Friday. Free, always.